Tutorial
Deep Learning with Azure: PyTorch distributed training done right in Kedro
At GetInData we use the Kedro framework as the core building block of our MLOps solutions as it structures ML projects well, providing great…
Read moreOne of the biggest challenges of today’s Machine Learning world is the lack of standardization when it comes to models training.
We all know that data needs to be cleaned, split into training and test sets, fitted into the model and validated on the observations from the test subset. Maybe there should be some cross-validation involved, hyperparameters tuning is also not a bad idea. All Data Scientists feel how to work with the models efficiently, but a lack of common standards makes their work hard to understand for other engineers using a different methodology.
To overcome this issue, QuantumBlack open-sourced the Kedro framework, an open-source Python framework for creating reproducible, maintainable and modular data science code. Projects created with Kedro are universal enough to cover most of the tasks that Data Scientists may have. Additionally, Data Catalog and Pipeline abstractions make the model building process look like a software project that can be configured and deployed easily, especially by the engineers that didn’t take part in implementing them. It provides a variety of plugins to log models and metrics in Mlflow, ship the project as a docker image and more. Based on the feedback gathered from our clients, we made Kedro a core part of GetInData Machine Learning Operations Platform. We presented our MLOps platform blueprint during the Google Cloud Region launch in Warsaw. You can watch it here (currently only in Polish)
However, having a Kedro project ready and well tested on the data sample doesn’t mean it is ready enough to go “into production” and be deployed quickly. Continuous training, hyper parameter tuning, continuous quality validation - all these tasks need some scheduling capabilities, distributed computing and powerful hardware to do things efficiently. Kedro describes some ideas on how to deploy the models, but well, you know what they say, “work smarter, not harder - automate everything” ;-)
*Welcome to MLOps candy shop and choose your flavour! - Mateusz Pytel & Mariusz Strzelecki - Big Data Technology Warsaw Summit 2021*Kubernetes is the core of our Machine Learning Operations platform and Kubeflow is a system that we often deploy for our clients. Therefore, we decided to automate the generation of the Kubeflow pipeline from the existing Kedro pipeline to allow it to be scheduled by Kubeflow Pipelines (a.k.a. KFP) and started on the Kubernetes cluster. Thankfully, the creators of Kedro gave us a little help, by doing proof-of-concept of this integration and providing interesting insights.
The result of our work is available on GitHub as a kedro-kubeflow plugin. You install it in your existing Kedro project and soon you can:
We faced some challenges - for example Kedro expects the `data/` directory to be a place where nodes exchange the data, but in a distributed environment there are limited options to maintain shared storage between different processes. Thankfully, with a bit of hacking, we made it!
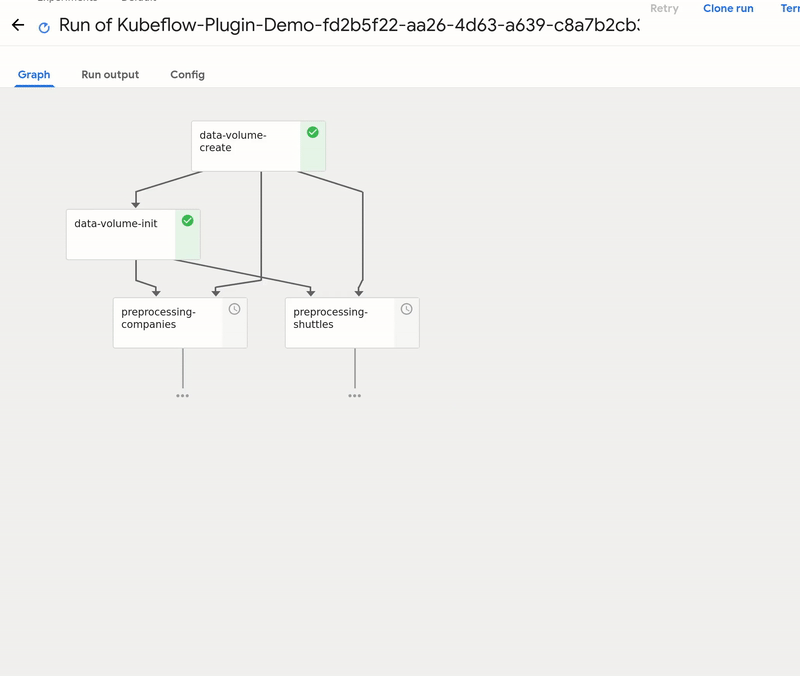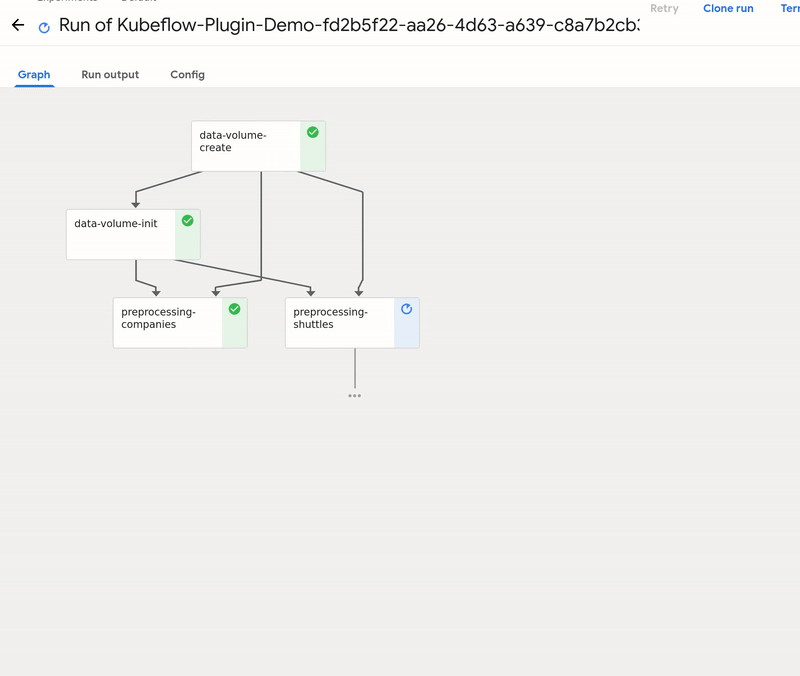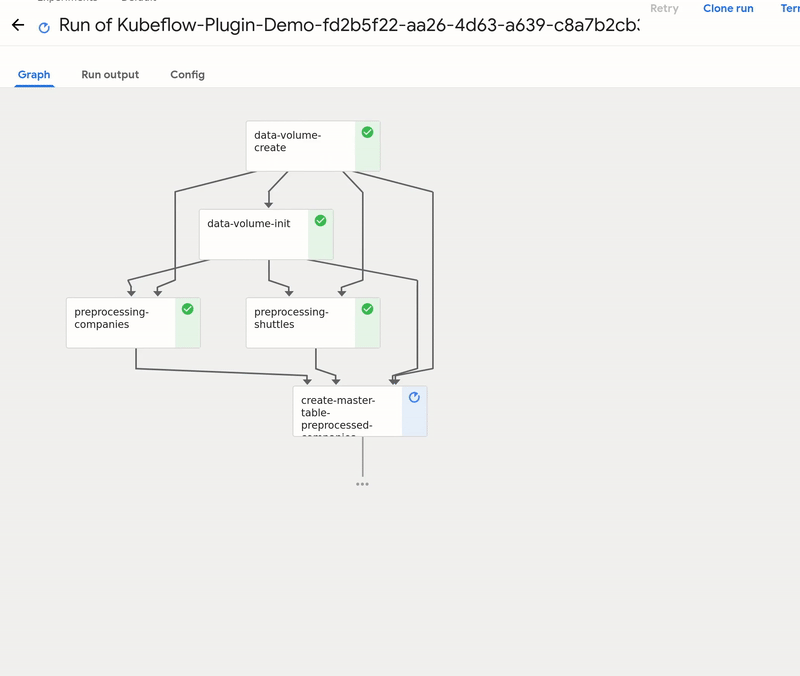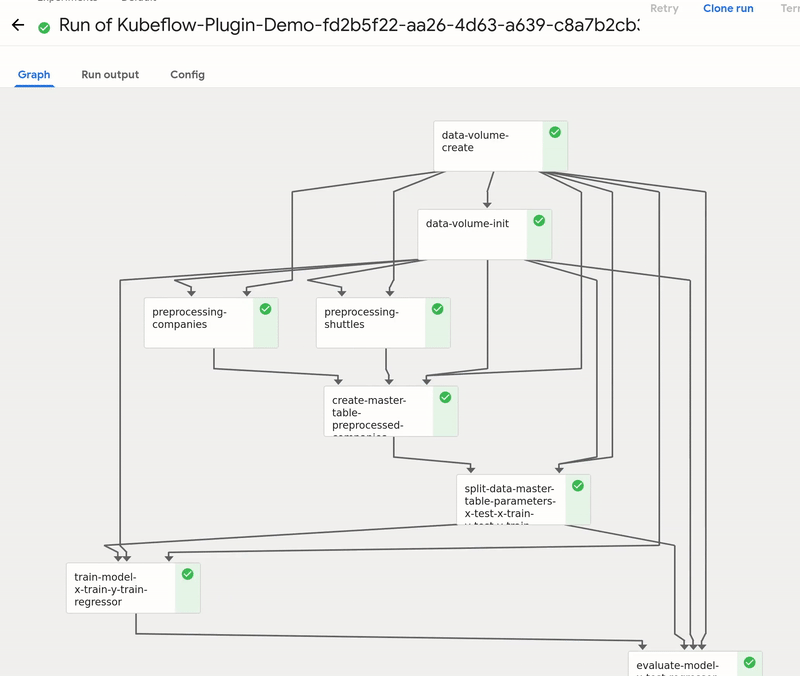 GetInData MLOps Platform: Kubeflow plugin
GetInData MLOps Platform: Kubeflow plugin
Some of our customers tend to avoid Kubeflow, as the system is quite complicated to install and maintain. Fortunately, Airflow can meet the same needs with Kedro pipeline deployment. There is an official kedro-airflow plugin, but it doesn’t support running in Docker containers inside a Kubernetes cluster which is our preferred, most universal method.
Therefore, based on the experience of developing kedro-kubeflow, we created another plugin that we called kedro-airflow-k8s. It has the same capabilities and even the same CLI syntax as its older brother, but compiles the Kedro pipelines to Airflow DAG and deploys it by copying the file to the shared bucket which Airflow uses to synchronize Dag Bag.

If you’re using Kubeflow, feel free to check quickstart and the rest of the documentation. If you’re using Airflow, we have quickstart as well. If you decide to give them a try - we’re waiting for your feedback! The plugins are in Beta phase, but the main API (the way you call it from Kedro CLI) is now stable, so don’t be afraid to integrate it into your CI/CD pipelines, as we did recently.
If you want to know more please check our Machine Learning Platform and do not hesitate to contact us.
At GetInData we use the Kedro framework as the core building block of our MLOps solutions as it structures ML projects well, providing great…
Read moreBig Data Technology Warsaw Summit 2021 is fast approaching. Please save the date - February 25th, 2021. This time the conference will be organized as…
Read moreIntroduction In the rapidly evolving field of artificial intelligence, large language models (LLMs) have emerged as transformative tools. They’ve gone…
Read moreIn data engineering, poor data quality can lead to massive inefficiencies and incorrect decision-making. Whether it's duplicate records, missing…
Read moreRemember our whitepaper “Guide to Recommendation Systems. Implementation of Machine Learning in Business” from the middle of last year? Our data…
Read moreBlack Friday, the pre-Christmas period, Valentine’s Day, Mother’s Day, Easter - all these events may be the prime time for the e-commerce and retail…
Read moreTogether, we will select the best Big Data solutions for your organization and build a project that will have a real impact on your organization.
What did you find most impressive about GetInData?